 JASNA CASE
JASNA CASE









 CARTOONS
CARTOONS

 DISCOUNT
DISCOUNT


|
NEWS | Apr 18
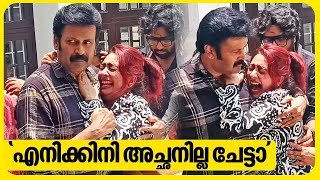
മമ്മൂട്ടിയും പൃഥ്വിരാജും
വീണ്ടും
|
|
NEWS | Apr 18
യഷിന്റെ ടോക്സിക്, കിയാരയും
|
|
SPONSORED AD
|
|
ERNAKULAM | Apr 19
ഗോഡൗണിൽ തീയിട്ട അന്യസംസ്ഥാന, തൊഴിലാളി പിടിയിൽ
|
|
KERALA | Apr 19
മയക്കുമരുന്നുമായി യുവാക്കൾ പിടിയിൽ
|




|
SPONSORED AD

|
|
NATIONAL | Apr 13
ഇന്ത്യൻ ജീവനക്കാരെ പിരിച്ചുവിട്ട് കാനഡ
|
|
NATIONAL | Apr 19
താൻ ഭഗവാൻ കൃഷ്ണന്റെ ഗോപിക: ഹേമമാലിനി
|



|
SPONSORED AD
|
|
COLUMNS | Apr 19
അവസാനിപ്പിക്കാം, ഈ ഒളിയുദ്ധം
|
|
COLUMNS | Apr 19
ക്യാമ്പസ് സുരക്ഷയും
മറുവശവും...
|

 HOME
HOME LATEST
LATEST NOTIFIED NEWS
NOTIFIED NEWS POLL
POLL KERALA
KERALA  LOCAL
LOCAL  OBITUARY
OBITUARY  NEWS 360
NEWS 360  CASE DIARY
CASE DIARY  CINEMA
CINEMA  OPINION
OPINION  PHOTOS
PHOTOS  LIFESTYLE
LIFESTYLE  SPIRITUAL
SPIRITUAL  INFO+
INFO+  ART
ART  ASTRO
ASTRO  CARTOONS
CARTOONS  LITERATURE
LITERATURE  ZOOM
ZOOM 























 KERALAKAUMUDI NEWS
KERALAKAUMUDI NEWS










 KAUMUDY
KAUMUDY






 1
1
